MandoMaster: AI-Powered Chinese Learning with Spaced Repetition
Hey there!
First off, MandoMaster is live and free to use, so if you're interested you can just take a quick look to see what I'm talking about.
Alright, time to write about another project of mine, this one is almost finished just waiting on a couple of finishing touches. I'm quite content with this one since it's one I actually added to my daily routine now, so there'll probably be little improvements down the line but for now things work as they should.
What is MandoMaster?
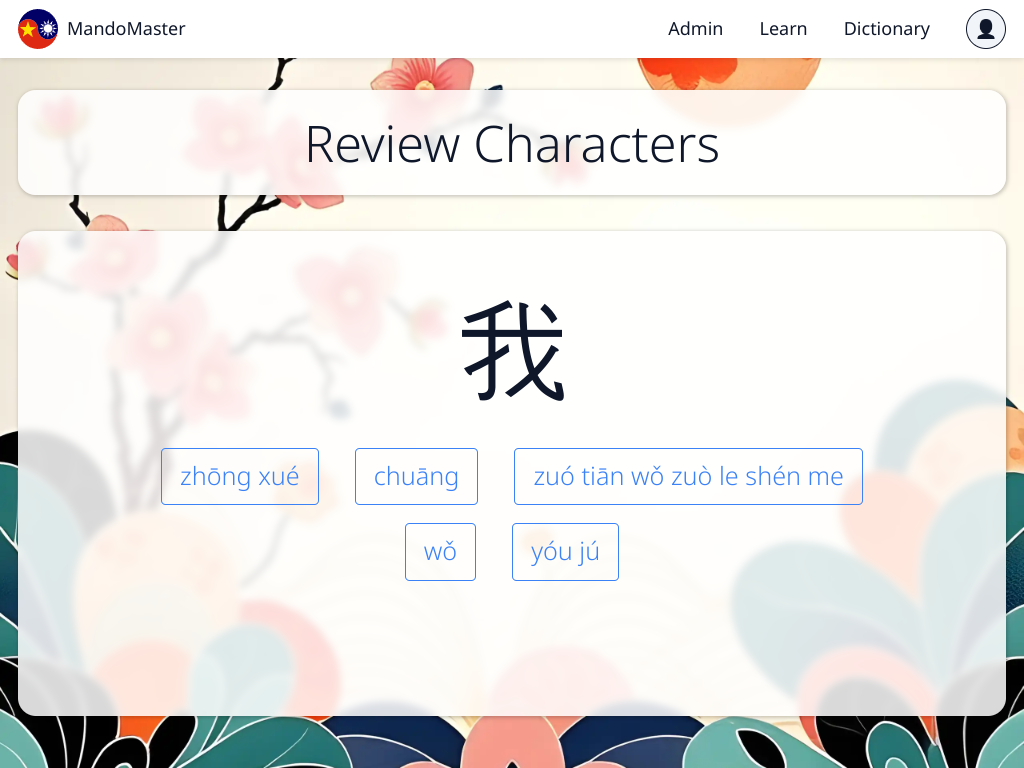
MandoMaster is a WebApp for learning Chinese making use of spaced repetition techniques to make memorization easier. I've wanted to do this since Pei started teaching me (traditional) Chinese and I kept forgetting things, now it's much easier since I'll just add any new words to my review pile.
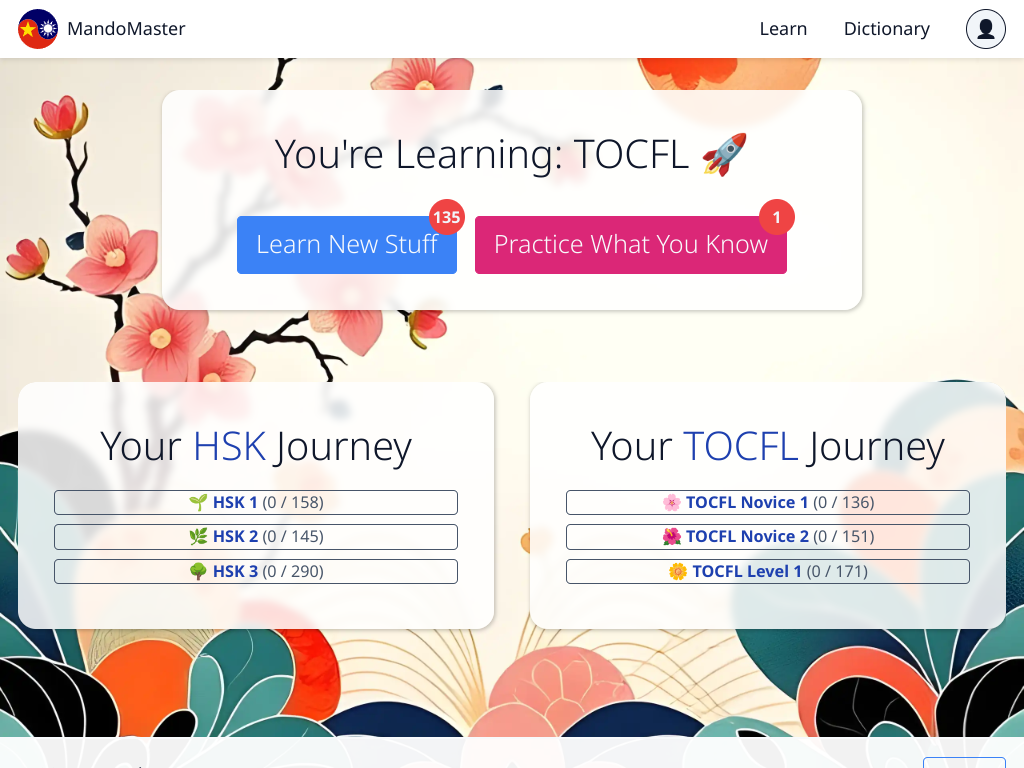
The way it works is that it's basically a huge dictionary with lots of metadata for each word/character. This can be basic stuff like the meaning of a character, or something like an audio sample of how it is supposed to be pronounced, or on which level of the HSK/TOCFL test it is required.
So what can it do?
Just to give you a quick rundown of what MandoMaster can do:
- It's got a massive dictionary with meanings, examples, and all that good stuff
- Spaced repetition that actually works (at least for me) to remember characters
- Audio samples so you can hear how words should sound
- The first HSK/TOCFL levels are in there if you're studying for those tests
- You can add stuff to your personal review pile
- Works fine on your phone too because who sits at a desk to study these days?
How I built it
Let me walk you through how I put this thing together. It was quite the journey but LLMs made a lot of things much easier than I expected.
Technical overview
The tech stack is very similar to bitmenu, mainly because I started this project off by making a copy of the bitmenu repo and then stripping out all the digital menu stuff. This actually worked really well and meant that I could focus on actually developing features specific to this particular idea, rather than doing generic boilerplate.
It was quite the challenge to build an app for learning Chinese when I only speak a couple of words. It helped to have a native speaker for asking questions as well as modern LLMs around. It's also amazing how much LLMs helped and actually made this possible.
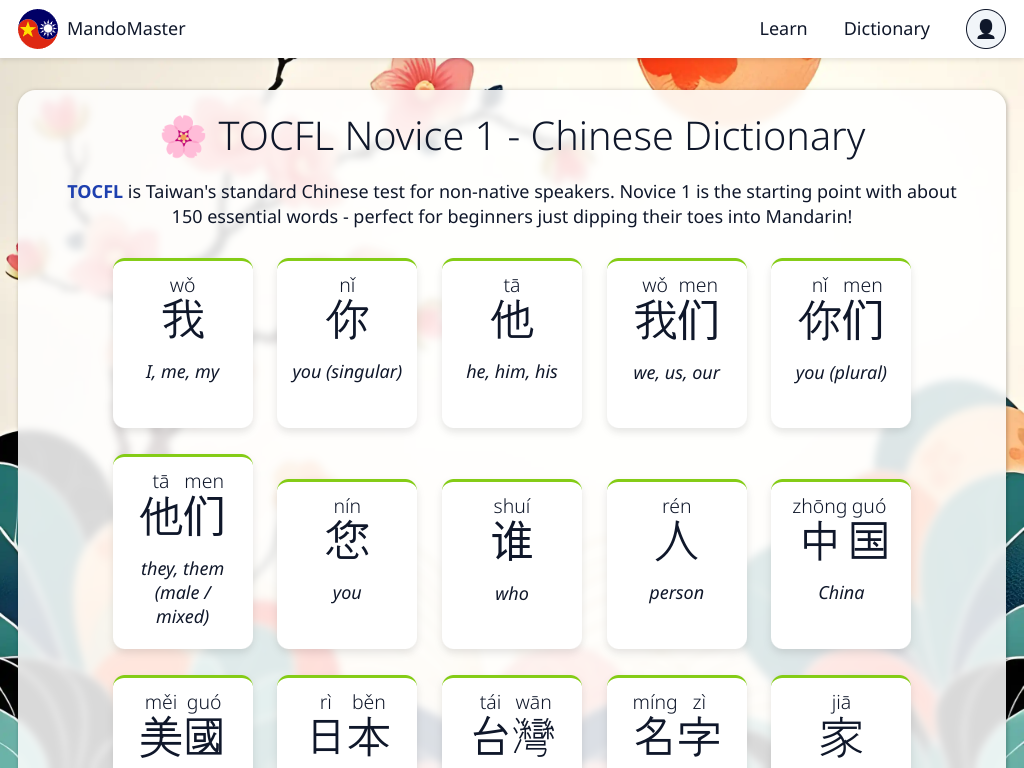
Building the Dictionary
This would have been a massive undertaking, luckily with LLMs this was quite the easy thing to do. I mainly worked by adding all the words from the first 3 levels of the HSK/TOCFL tests into a TypeScript source file like so:
我
你
// ... and on and on
Then used search/replace on every new line to turn this into the following:
{ id: "我"},
{ id: "你"},
// ... and on and on
Now I can just manually add some surrounding syntax to turn this into valid TypeScript:
export const hsk1Words: DictionaryEntry[] = [
{ id: "我"},
{ id: "你"},
// ... and on and on
];
Now we can just run an auto formatter to get some nice looking code. However we don't just want the words, but also the meaning and other important metadata (we can ignore the pinyin/reading, there are libraries for that). Now I could just let the LLM go wild on this file and have it produce the other fields:
export const hsk1Words: DictionaryEntry[] = [
{
id: "我",
meaning: "I, me, my",
type: "personal pronoun",
description: "The most common way to say 'I' or 'me' in Chinese. Used as the subject or object in sentences to refer to oneself.",
},
{
id: "你",
meaning: "you (singular)",
type: "personal pronoun",
description: "The standard way to say 'you' in Chinese. Used in informal situations or when addressing someone of similar or lower status.",
},
// ... and on and on
];
One-shotting things doesn't always work though, and I've had the best results making things in multiple steps:
- First, I asked the LLM to write the meaning/type and a short description
- Then ran it again (sometimes with another model) to check the first results
- Finally just did some quick manual checks to make sure things weren't completely wrong
Checked about 15 entries thoroughly and the meanings/descriptions seem to be accurate from what I can tell. Really nice since this would've been a massive undertaking before, now it just took me a couple hours to build up a massive dictionary.
Adding Voice samples
This one would have been really problematic before, but modern Text to Speech models produce really good output. Searched the web for some samples and really liked the way Amazon's Zhiyu sounded, also had a very simple API and a free tier.
So I used Cursor to write some code that on startup checks every dictionary entry and sees whether there's a voice sample available (it's just a directory called /voice containing MP3's). If not, it creates the file using the Amazon Polly API.
Worked great and Cursor one-shotted it, so the actual coding took me a couple of minutes. I actually spent more time generating the API token on AWS than it took the LLM to write the code. Now I just added a simple rsync script so that I could synchronize the voice samples between my dev machine and the production server (that way we don't need to generate the same sample twice).
Experimenting with SEO
This one I've been struggling with, thought it might be a good project to check out best practices for SEO and in general depend on search engines to generate traffic. It kind of works but not as much as I'd like to.
I suppose one of the good things is that due to the dictionary there is a lot of very specific content people might actually search for (think "what does 你 mean?"). This part still isn't done and I quite enjoy using MandoMaster as an SEO testbed.
Future development
While these might take a while, I'd really like to add these features in the coming weeks. Here are a couple of ideas I'm particularly excited about:
Better search
While there already is a very basic search, it's not that great. I'd love to have one as sophisticated as jisho which can also understand sentences and split them up so you can check things out one word/character at a time. Might also be interesting to add some LLM integration here that could explain the overall structure of the sentence.
Example sentences / LLM Tutor
No idea how well this might work, but it might be great to have an LLM generate example sentences in English based on the knowledge of the user which they then need to write in Chinese. This would get checked by the LLM that hopefully produces sensible feedback about how well things are written.
Conclusion
Real fun project, started it about 3 weeks ago and now I've got something that works good enough for me to use on a daily basis to improve my Chinese. Getting more and more impressed by LLMs and how one can utilize them to create content that would have taken weeks/months before.
Although I won't focus as much on this anymore, I'll still improve things just for my own sake. I'd also like to figure out how to directly utilize LLMs for teaching, since I'm starting to get to a level where I'm able to build sentences myself and having somebody tell you whether it's right or wrong or how to improve things would be great (hope that LLMs are capable of that, though it'd be surprising if not since I'm only capable of super simple beginners Chinese).